


19 Commonly confused IT terms
January 12, 2026
5 minute read

We’ve all been there: you’re in a meeting trying to explain a complex system, and you find yourself using ‘path’ and ‘route’ interchangeably, even though you know they aren’t quite the same thing. In the world of IT and SaaS management, certain terms are notoriously difficult to pin down or explain to colleagues without a bit of head-scratching. To save you from future ‘well, actually’ moments, I’ve broken down the most commonly confused terminologies with relatable examples to help you keep your definitions—and your credibility—sharp.
Path vs. route
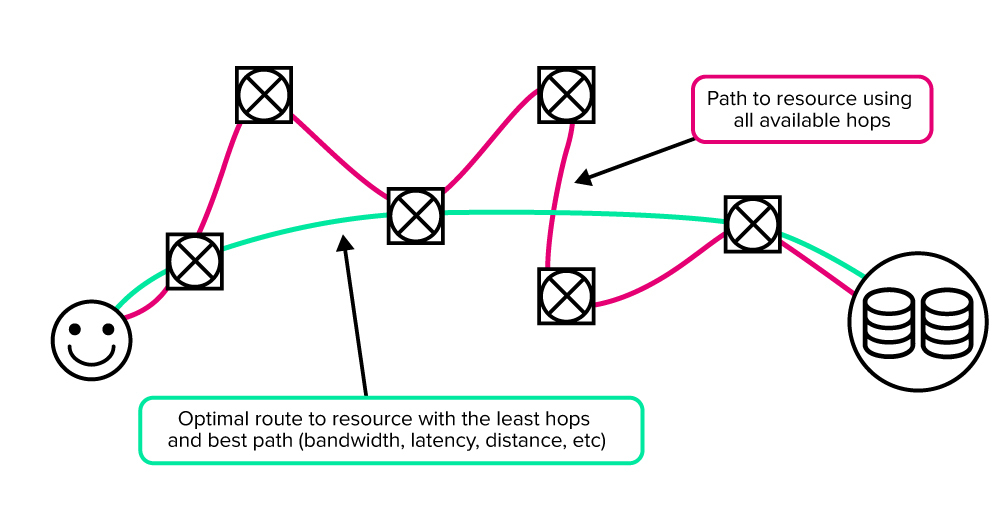
In networking context:
A path is a series of steps or number of hops to a destination without taking into account the link’s parameters between the source and destination. Think hopscotch. A route is usually the most optimal path to a destination from the source taking into account all the links’ parameters (latency, bandwidth, number of hops, physical location, etc.).
High availability vs. fault tolerance
Both offer redundancies and describe methods of fulfilling the obligation of high levels of SLA. However, they are significantly different.
Fault-tolerant resources (hardware or software) are such that two or more of the same resources are mirrored and function in tandem. The service is maintained in the event of an outage (which is usually transparent to the requestor). In most cases (if not all), the original request is still served without the resource being called again.
Highly available resources are such that there is a primary (higher capacity/performance) and secondary/backup resource (mirror or usually less capacity) in operation. Where the primary fails, the backup assumes the primary role until the primary resource is restored. There is usually downtime associated with switching between primary and secondary resources and vice versa.
Fault-tolerant systems are usually implemented on mission-critical services that require real-time operations where any momentary timeout (in milliseconds) could have a significant impact on the service. It comes with a high price tag.
A fault-tolerant system remains in operation even after any of its participating components goes down.
Highly available systems resume operations usually within a short period after a participating component (usually the primary/master) fails or resumes function.
As an example, consider a router with redundant power supplies (fault-tolerant) and dual ISP connections (highly available). If any of the power supplies fails, the router remains functional. However, if the primary ISP link goes offline, there would usually be a brief timeout (heartbeat) before the backup link assumed the primary role.
API keys vs. authentication tokens
API keys are used to authorize access to a resource and (usually) grant read-only access. These keys are usually persistent and live beyond the lifetime of the established session they were used for.
Authentication tokens (auth tokens) authenticate a user to grant them permissions to access a resource. These permissions are based on predefined rules (read, write, etc.). Auth tokens are generated for each session a user authenticates against a service and live for as long as the session remains active.
Repository vs. resource pool
A repository is a collection of various resources which may or may not conform to any structure or belong to a class of similar resources. A repository can be used to store files (of any format) or can be a repository of repositories.
- A resource is a computing component used for a specific task.
A resource pool is a set of resources — with generally similar attributes or are interconnected — available either shared or dedicated exclusively for a specific set of tasks or function (e.g., CPU, storage, RAM, etc.). A resource pool is generally structured and only resources of similar types conforming to the defined functions are (usually) available.
Integration vs. connector
In the SaaS world and generally in managing any application platform, these terms come up more often than you notice. Sometimes their usage is contextually interchanged. There may be high level similarities in function; however, these two terms (technologies) are different.
An integration is when two or more systems/applications are linked such that a process cannot be completed when a participating service of the integration is unavailable. As an example, think of identity federation where access would not be granted to a user if the identity provider was unreachable.
A connector gives you access to, and lets you leverage, a prepackaged set of actions that are performed against an integration.
To put into perspective, the BetterCloud Integration Center has tons of native integrations to work with (56 at the time of writing this article) with each having several connectors to complete specific actions.
So to use BetterCloud to manage G Suite, you’d need to integrate both platforms (which BetterCloud has handled), then use the connectors to perform actions when you create a workflow (e.g., suspend an email account when the user is moved to a specific OU).
URI vs. URL vs. URN
There’s been an age-long debate about the meaning of these terms.
Uniform Resource Identifier (URI) — Specifies the various characteristics and traits of a particular resource which may include its identifier and mechanisms with which it can be accessed. (SaaS company, physical address, BetterCloud, website)
Uniform Resource Locator (URL) — Specifies where a specific resource is located and the associated mechanism that can be used to access it. (BetterCloud, physical address, floor number, SaaS company, services offered, service link, website, service demo, etc.)
Uniform Resource Name (URN) — A globally unique identifier of a resource that does not specify anything else about the resource (or where it is located and mechanisms to access it). (BetterCloud company registration number)
URLs and URNs are generally subsets of URIs but not the other way around.
LLM vs. Agentic Workflow
By 2026, IT professionals are no longer just managing chatbots; they are managing autonomous agents.
LLM (Large Language Model): A static model that predicts the next token in a sequence to generate text or code. It is a “brain in a jar.”
Agentic Workflow: A system where an LLM is given tools (like an internet browser or code execution) and the autonomy to complete a goal through multiple iterative steps.
Zero Trust vs. SASE (Secure Access Service Edge)
While “Zero Trust” was a buzzword in 2020, by 2026 it is a mandatory architecture, often confused with the framework that delivers it.
Zero Trust: A security philosophy centered on the belief that no entity inside or outside the network should be trusted by default (“Never trust, always verify”).
SASE: The actual architecture that combines networking (SD-WAN) and security (Zero Trust, Firewall-as-a-Service) into a single cloud-delivered service.
Fine-Tuning vs. RAG (Retrieval-Augmented Generation)
As IT teams manage internal AI apps, these two methods of “teaching” an AI are frequently confused.
Fine-Tuning: Permanently training a model on a new dataset to change its behavior or style. It is expensive and the data becomes “baked in.”
RAG: Connecting a model to a live database or repository to look up information before answering. It ensures the AI has access to real-time, factual data without needing a retraining session.
In conclusion, you may not harm anything or anyone if you mix up these terms. However, some folks won’t be able to enjoy their coffee every time they hear any of these mixed up. By knowing the distinction between these terms, you’ll quickly build credibility and establish your expertise in the organization.


